

Why GraphQL
Before we dive into writing a query, let's touch a bit on the why of GraphQL when we already have SQL. SQL is the language we use to build and access relational databases, which, according to some IBM and Oracle employees, stand as computer science's greatest accomplishment. Others might consider giphy to be the pinnacle of software, decide for yourself.
Then some day someone comes by and asks for a simple api to one of your databases. At first it's just a little thing, "We just need to integrate your database with our CRM, we only need to see orders." So you write a little REST API and everyone is happy. For awhile. Then someone else asks for a slightly different API to hook up some new mobile app. At first you just offer them the API you wrote for the CRM team but the mobile people want something slightly different. You could modify the original API but that would break the CRM integration so you create a second API.
The next thing you know you have a dozen REST APIs going in and out of your database. Then the CRM people come back and ask to integrate with the shipping database. You're no longer doing the thing you love which is keeping your database nice and organized, backed up and secure, and with highly optimized queries and 99.999% uptime. No, you're now versioning and documenting APIs all day and dealing with frantic slack messages about the field whose type you recently changed and how that took down $10k/day in mobile sales.

GraphQL let's you provide a consistent, extensible API to your back-end systems. Since GraphQL doesn't specify how or where data is stored, you are free to connect to SQL, noSQL, files, REST endpoints, or really almost any kind of data source. Furthermore, GraphQL lets you bundle many queries into a single network (http) request which returns only the data you asked. This really improves the performance and user experience of applications, particularly mobile apps.
Most of the time your GraphQL API will be talking SQL to your database(s).
Setup
To see this example in action, you'll want to switch to the firstQuery branch of the repo. Assuming you've already cloned the repo, setup postgres and loaded the data (see part 1), do:
$ git checkout firstQuery
$ npm install
$ npm start
No More Chit-Chat, Let's Run a Query!
As you'll recall from part 1, we have a database with 9 tables modeled as 9 GraphQL types. One of the simplest of these is the Airport type. There are only a few hundred airports in the database so let's list them.
First add a query to our GraphQL *typeDefs`:
type Query {
"""
Return all airports in the database
"""
allAirports: [Airport]
}
This tells our GraphQL server that we want a query called allAirports that returns an array of Airport types. We're going to need to write some SQL to get all the airports, but where do we put that?
A quick tour through the source code of the demo:
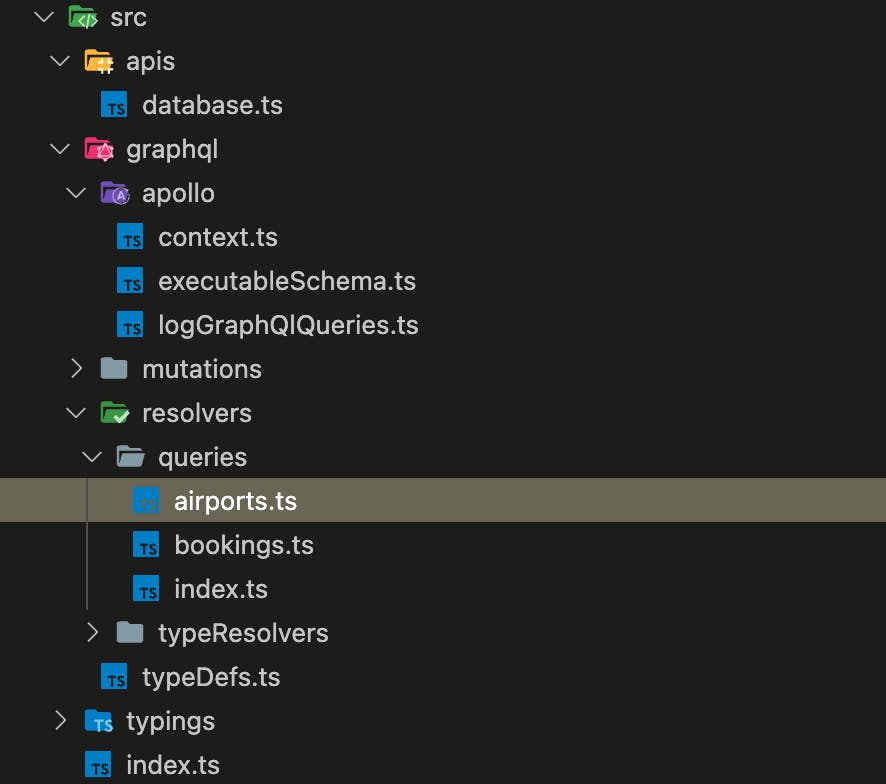
src/index.ts at the bottom of that image contains the entry point for our server. There we instantiate the Apollo GraphQL server based on an executable schema we've defined in src/graphql/apollo/executableSchema.ts. The executableSchema is built from the type definitions in src/graphql/typeDefs.ts as well as our query resolvers and mutations (a future topic).
export const schema = makeExecutableSchema({
typeDefs,
resolvers: {
...scalarResolvers,
...typeResolvers,
...queryResolvers,
...mutations,
},
});
I personally like to differentiate between query resolvers and type resolvers. The former run actual queries while the latter resolve fields in types. In either case a resolvers is something that fetches data to populate the JSON result that the GraphQL server will eventually send back to the client.
If you follow the chain of imports down you'll eventually come to src/graphql/resolvers/queries/airports.ts:
export const allAirports = () =>
database('airports_data')
.columns({ id: 'airportCode' }, '*')
.orderBy('airportCode')
.select();
In this demo I'm using the knex query builder package. This is an npm package that gives you javascript access to various kinds of databases including postgres here. It is setup in src/apis/database.ts.
Don't forget to copy
.env-templateto.envand setup your database credentials!
The above javascript code runs the following SQL:
select "airport_code" as "id", *
from "airports_data"
order by "airport_code" asc
the .columns({ id: 'airportCode' }, '*') is necessary here to alias the airportCode column as id which we defined in our GraphQL model for consistency. We're also taking all the other columns.
When querying a table we typically take all the columns so that our resolvers can (optionally) have direct access to all those values without requiring an additional query.
If you navigate to Apollo Studio on localhost:4000 you should now be able to run the following query:
query aa {
allAirports {
id
airportCode
timezone
coordinates {
x
y
}
}
}
You should then see results like:
{
"data": {
"allAirports": [
{
"id": "AAQ",
"airportCode": "AAQ",
"timezone": "Europe/Moscow",
"coordinates": {
"x": 37.34730148,
"y": 45.0021019
}
},
{
"id": "ABA",
"airportCode": "ABA",
"timezone": "Asia/Krasnoyarsk",
"coordinates": {
"x": 91.38500214,
"y": 53.74000168
}
},
…
}
Note that the knex package automatically transformed the
POINTtype in thecoordinatesfield in theairports_datatable to an object with x and y keys. Had we chosen different names we would need a resolver to manage the aliases.
Field Resolvers for the Airport Type
The Airport type has a little wrinkle. The airports_data table defines the airport_name and city fields as a JSONB field where the human readable name is keyed by language.
If you look at src/graphql/apollo/context.ts you'll see that we're capturing the accept-language header from the client and using that to set a human language to be used when returning results.
export const context = async ({ req, res }: tContext) => {
// our data is in English and Russian. Figure out which language
// the client is requesting, defaulting to 'en'
req.language = req.acceptsLanguages('en', 'ru') || 'en';
return { req, res };
};
Now look at src/graphql/resolvers/typeResolvers/index.ts and you'll see this definition for the Airport type:
Airport: {
airportName: (
{ airportName }: tAirportName,
_: object, { req }: tContext
) => airportName[req.language],
city: ({ city }: tCity, _: object, { req }: tContext) =>
city[req.language],
}
If you're not yet familiar with TypeScript you might find this a bit hard to read so here's a simpler version without TypeScript annotations:
Airport: {
airportName: ( { airportName }, _, { req }) ) =>
airportName[req.language],
city: ({ city }, _, { req }) => city[req.language],
},
Please refer to the Apollo documentation for the definition of resolver function arguments.
The context is set before any resolvers run so we can depend on req.language existing. In the resolvers for airportName and city we can then simply reference the human language value by that key.
We can now run a more complete query on airports. And for grins lets set the accept-language header to ru.

We should now see the airports data with all the fields:
{
"data": {
"allAirports": [
{
"id": "AAQ",
"airportCode": "AAQ",
"airportName": "Витязево",
"timezone": "Europe/Moscow",
"coordinates": {
"x": 37.34730148,
"y": 45.0021019
}
},
{
"id": "ABA",
"airportCode": "ABA",
"airportName": "Абакан",
"timezone": "Asia/Krasnoyarsk",
"coordinates": {
"x": 91.38500214,
"y": 53.74000168
}
},
A Parameterized Query
The allAirports query doesn't do any filtering - it just returns all the records in the airports_data table. Let's create a simple query that takes a single parameter and returns a single object. If you look at the typeDefs you'll see:
oneBooking(reference: String!): Booking
under the Query type definitions. This query is intended to return a single Booking object based on the booking reference. The query is implemented in src/graphql/resolvers/queries/bookings.ts
export const oneBooking = (
_: object,
{ reference: bookRef }: tReference) =>
database('bookings')
.where({ bookRef })
.columns(
{ id: 'bookRef' },
{ reference: 'bookRef' },
{ bookedAt: 'bookDate' },
'*'
)
.first();
Here we're doing a bit of aliasing in both directions. The query parameter is named reference but the database itself uses book_ref as the column name for the booking reference.
I'm using the very convenient
knex-stringcasepackage to map (javascript) camelCase variable names to (SQL) snake_case and vice-versa.
This code:
.columns(
{ id: 'bookRef' },
{ reference: 'bookRef' },
{ bookedAt: 'bookDate' },
'*'
)
ensures that we create a synthetic id field from the query. The bookRef and bookDate fields are also renamed to what we have defined in the model. The reference and id fields are clearly redundant but as explained in part 1, a 6 character code only gets you 308 million records. We're anticipating using a more flexible id in the future and the extra alias doesn't cost us anything in storage.
Using Apollo Studio we can run the following query:
query ob($reference: String!){
oneBooking(reference: $reference){
id
reference
bookedAt
totalAmount
}
}
At the bottom of the Operations pane we can specify the value of the reference parameter:

Running the query results in:
{
"data": {
"oneBooking": {
"id": "E170C3",
"reference": "E170C3",
"bookedAt": "2017-06-28T22:55:00.000Z",
"totalAmount": 24700
}
}
}
The SQL generated by Knex is:
select
"book_ref" as "id",
"book_ref" as "reference",
"book_date" as "booked_at",
*
from "bookings"
where "book_ref" = ? limit ?
bindings: [ 'E170C3', 1 ]
Resolver for the related tickets
The Booking type includes this field definition:
tickets: [Ticket]
i.e. we should be able to the tickets that are related to a booking. We need a field resolver for the tickets field that does that lookup. Looking again at src/graphql/resolvers/typeResolvers:
Booking: {
tickets: ({ id: bookRef }: { id: string }) =>
database('tickets')
.where({ bookRef })
.columns({ id: 'ticketNo' }, '*')
.select(),
},
Now we can run a more complete query except that we also need to resolve the passenger field of the Ticket type. Just below the Booking resolver we can see the code for the passenger resolver; its sole job is to remap the fields that came out of the database into an object.
Ticket: {
passenger: ({
passengerId: id,
passengerName: name,
contactData: { email, phone },
}: tPassenger) => ({ id, name, email, phone }),
},
With that in place, in Apollo Studio run:
query ob($reference: String!){
oneBooking(reference: $reference){
id
reference
bookedAt
totalAmount
tickets {
id
passenger {
id
name
phone
email
}
}
}
}
With the same reference variable value of 'E170C3'. The results should be:
{
"data": {
"oneBooking": {
"id": "E170C3",
"reference": "E170C3",
"bookedAt": "2017-06-28T22:55:00.000Z",
"totalAmount": 24700,
"tickets": [
{
"id": "0005432000989",
"passenger": {
"id": "1011 752484",
"name": "ARTUR GERASIMOV",
"phone": "+70760429203",
"email": null
}
},
{
"id": "0005432000990",
"passenger": {
"id": "4849 400049",
"name": "ALINA VOLKOVA",
"phone": "+70582584031",
"email": "volkova.alina_03101973@postgrespro.ru"
}
}
]
}
}
}
In this case there are two tickets attached to the booking. With one query we've fetched all the information in the booking as well as the key information in the two attached tickets.
Looking at the SQL that ran to satisfy the initial query we can see:
select
"book_ref" as "id",
"book_ref" as "reference",
"book_date" as "booked_at",
*
from "bookings"
where "book_ref" = ? limit ?
bindings: [ 'E170C3', 1 ]
followed by:
select "ticket_no" as "id", * from "tickets" where "book_ref" = ?
bindings: [ 'E170C3' ]
This illustrates that rather than doing a JOIN to go after both the bookings and tickets tables at the same time, graphql runs a SQL query to get the booking first followed by a second SQL query to get the related tickets. If we were to omit the tickets field from out graphql query we'd only see the first query execute.
Summary
In the post above we have hooked up a GraphQL server to a postgres database through the use of resolvers and run some (relatively) simple queries. We've arbitrarily differentiated between query resolvers that execute entire queries and type resolvers that simply fill in the data for GraphQL fields. We've also seen how a single GraphQL query can result in the execution of multiple SQL queries.
Up Next
Another question I've seen asked is some variation "Do you ever do a JOIN in GraphQL?" In the next part we'll illustrate some cases where SQL JOINs might be used when writing a resolver.